IA et algorithmes : conseiller sans manipuler
Si l’IA peut se montrer une alliée des consommateurs pour leur recommander des produits, elle est à manier avec précaution. Car, si le consommateur veut bien être conseillé, il ne veut pas être manipulé. Ni se sentir espionné. Les systèmes de recommandation utilisant l’intelligence artificielle (IA) ne sont plus réservés aux géants mondiaux comme Amazon ou Netflix. Ils deviennent accessibles à des entreprises de toutes tailles. Par exemple en France, des firmes, comme La Redoute ou Cdiscount, utilisent des recommandations IA pour personnaliser les expériences d’achat en ligne de leurs clients. Ces investissements signalent l’importance de ces technologies dans la croissance du commerce numérique. Selon le rapport Statista de 2024 (Statista Report 2024), ces systèmes influencent près de 35 % des achats en ligne démontrant leur impact considérable sur le comportement des consommateurs. Cependant, les consommateurs français sont exigeants et attachés à leur vie privée. Une enquête menée par PwC France a révélé que deux tiers des consommateurs français sont préoccupés par le partage de leurs données personnelles. Pour les commerçants et autres gestionnaires de plates-formes, il est essentiel de réussir à tirer tous les bénéfices de ces nouveaux systèmes de recommandation, sans fâcher les consommateurs.
par Zi WANG Professor in Marketing, IÉSEG School of Management dans The Conversation
Zi WANG est membre de LEM (Lille Economie Management).
Ce défi est accentué par le cadre juridique strict en France et dans l’Union européenne, notamment avec le RGPD (Règlement général sur la protection des données), le DSA (Digital Services Act, DSA) et l’utilisation des plates-formes de gestion de consentement (Consent Management Platform, CMP). Ces réglementations obligent les entreprises à garantir la transparence des algorithmes et à respecter le consentement des utilisateurs lors de la collecte et du traitement de leurs données personnelles.
De plus, la CNIL (Commission nationale de l’informatique et des libertés) veille à l’application rigoureuse de ces règles en France, renforçant ainsi la responsabilité des entreprises face aux attentes des consommateurs en matière de confidentialité et d’autonomie. Dans ce contexte, trouver un équilibre entre personnalisation de l’expérience et respect de la vie privée est un défi essentiel pour les entreprises. La clé de cet équilibre réside dans la compréhension de deux aspects critiques :
- l’intuitivité de l’expérience, qui garantit des interactions fluides et satisfaisantes ;
- et l’intrusion, qui risque d’agacer les utilisateurs et de nuire à la relation avec la marque.
Dans notre étude, publiée dans le Journal of Consumer Behaviour, nous avons interrogé des consommateurs pour explorer l’impact des systèmes de recommandation d’IA sur leur bien-être « technologique ». Cinq caractéristiques clés qui façonnent les réponses des consommateurs ont été identifiées :
- l’optimisation de l’information : pour améliorer la pertinence et la qualité des recommandations. Par exemple, un système de recommandation des livres peut s’appuyer non seulement sur les achats antérieurs, mais aussi sur des informations comme les avis précédents, le temps passé sur chaque page et les tendances actuelles. Cela garantit des suggestions qui correspondent précisément aux goûts de la personne ;
- l’automatisation simplifie les choix en réduisant l’effort décisionnel. Par exemple, une plate-forme de streaming comme Netflix génère automatiquement une liste de lectures personnalisées. Cela réduit ainsi le temps et l’effort nécessaires pour décider quoi regarder ;
- la personnalisation offre aux utilisateurs la possibilité d’adapter leurs expériences, tout en augmentant leur satisfaction. Dans ce cas, on peut imaginer l’exemple d’une boutique en ligne où les préférences sont ajustables, comme choisir des couleurs ou des tailles spécifiques, le but étant de voir uniquement les produits qui correspondent à vos critères personnels ;
- l’« humanité » désigne un système qui se rapproche du comportement humain pour créer un sentiment de familiarité, à l’instar d’un assistant vocal qui utilise un ton chaleureux et engageant, créant l’impression de discuter avec un humain plutôt qu’avec un programme informatique.
Intuitifs, mais pas intrusifs
Nos résultats montrent que, globalement, les systèmes perçus comme intuitifs améliorent la satisfaction des utilisateurs et la prise de décision. En revanche, les systèmes jugés intrusifs – en particulier ceux qui collectent des données personnelles de façon excessive – sapent la confiance et génèrent de la frustration.
Spécifiquement, le graphique ci-dessous montre les effets positifs et négatifs des systèmes de recommandation d’intelligence artificielle sur les consommateurs, en mettant en lumière les avantages et les risques de ces technologies. D’un côté, des aspects comme l’optimisation de l’information et la personnalisation sont présentés comme des points forts. Par exemple, les recommandations permettent aux utilisateurs de trouver plus rapidement des produits ou des contenus qui les intéressent. La personnalisation améliore également leur satisfaction en adaptant les suggestions à leurs goûts spécifiques, rendant leur expérience plus agréable et engageante.
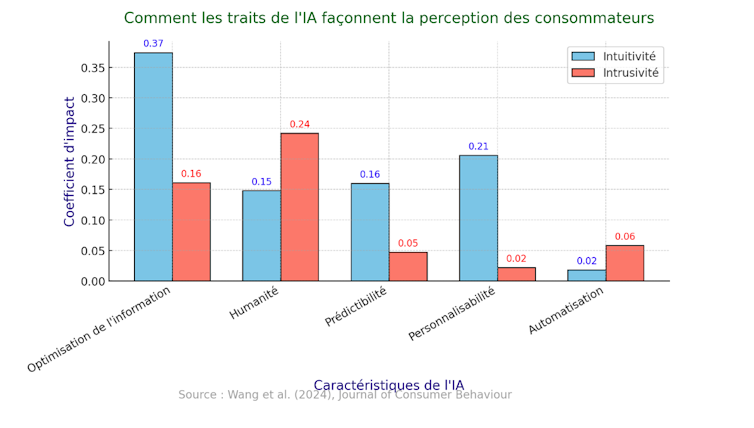
Cependant, le graphique souligne aussi certains risques. Une automatisation excessive peut donner l’impression aux consommateurs qu’ils perdent le contrôle sur leurs choix. De même, une utilisation excessive des données personnelles sans transparence peut créer un sentiment de méfiance ou d’intrusion dans leur vie privée.
En résumé, ce graphique montre que, bien que les systèmes d’IA puissent offrir des avantages importants aux consommateurs, il est essentiel pour les entreprises de les utiliser avec précaution, en respectant la vie privée et en évitant de les laisser devenir trop intrusifs.
Ainsi, nos résultats démontrent que les entreprises peuvent améliorer l’intuitivité des systèmes d’IA en se concentrant sur la simplicité et la pertinence. Par exemple, un caviste pourrait utiliser l’IA pour suggérer des accords vins et mets en fonction des achats précédents, rendant l’expérience d’achat plus simple pour les clients.
Pour ne pas crisper les clients, les entreprises devraient limiter la fréquence des notifications générées par l’IA et assurer la transparence de l’utilisation des données. Par exemple, elles peuvent proposer des options très claires pour contrôler ou désactiver les recommandations. Ainsi, elles peuvent espérer renforcer la confiance de leurs clients.
Les entreprises peuvent également donner la possibilité à leurs consommateurs d’ajuster les paramètres de leurs recommandations afin d’augmenter le sentiment de contrôle. Une boutique de mode en ligne, par exemple, pourrait laisser les utilisateurs filtrer les produits par style, garantissant que les suggestions correspondent à leurs préférences.
Des recommandations précises et fiables sont tout aussi essentielles pour gagner la confiance des consommateurs. Des mises à jour régulières des algorithmes, basées sur les retours des utilisateurs, garantissent que le système évolue en accord avec les besoins des consommateurs.
Cependant, nos recherches soulignent également que même les recommandations intrusives peuvent parfois améliorer la satisfaction des utilisateurs – à condition qu’elles soient très pertinentes. Par exemple, un système qui propose des offres de vacances au bon moment pourrait être bien accueilli par un client hésitant.
Les systèmes de recommandation d’IA sont des outils puissants qui, s’ils sont bien utilisés, peuvent stimuler la satisfaction des clients. Nos résultats mettent en avant que les entreprises utilisant de tels systèmes devraient prendre en compte trois éléments clés :
- elles doivent privilégier l’expérience utilisateur en concevant des systèmes qui simplifient les décisions sans submerger les utilisateurs avec des notifications ;
- elles doivent se focaliser sur la transparence de leurs systèmes en communiquant clairement sur la collecte et l’utilisation des données ;
- elles doivent investir dans la personnalisation de ces outils, afin de permettre aux clients eux-mêmes de personnaliser leurs recommandations pour une expérience adaptée.
Les entreprises qui trouveront le bon équilibre entre utilité et respect de l’autonomie des clients se démarqueront sur un marché numérique très concurrentiel.